

IBM推出了合成数据生成技术,旨在改变全球聊天机器人的能力。这种名为大规模对齐聊天机器人(Large-scale Alignment for Chatbots,LAB)的方法有望解决现代聊天机器人面临的长期挑战。
聊天机器人因其模仿各种角色的能力而受到关注,从海盗到会计师,但它们的表现经常因不准确和离题而犹豫不决。这种不一致源于他们的训练数据的局限性,这些数据主要来自互联网,并补充了特定于任务的信息。
在LLM的支持下,聊天机器人在原始文本上进行预训练,以掌握语言的细微差别。然而,教学数据的质量仍然是一个重大障碍,人工生成的数据证明是费力和昂贵的,而合成数据缺乏多样性。
IBM的LAB方法提供了一种系统的方法来克服这些障碍。通过生成针对特定任务的合成数据,并将新知识无缝集成到基础模型中,LAB有望显著增强聊天机器人的能力。这种方法减少了通常与LLM培训相关的时间和成本,并确保了更健壮和通用的性能。
LAB的引入标志着聊天机器人技术发展的关键时刻,可能会重塑这些虚拟助手与不同领域用户的互动方式。随着企业和行业越来越依赖聊天机器人来提供客户服务、信息传播和任务自动化,IBM的创新解决方案可能预示着对话人工智能效率和有效性的新时代的到来。
什么是合成数据生成?
合成数据生成是指创建新数据,可以手动使用Excel等工具,也可以通过计算机模拟或算法自动生成新数据,以替代实际数据。这个过程包括从现有数据集中生成假数据,或者在真实数据不可用的情况下创建一个全新的数据集。生成的数据与原始数据非常相似,可以在任何时间、任何位置以任何大小生成。
尽管具有人工的性质,但合成数据在数学上或统计上复制了现实世界的数据,类似于从实际物体、事件或用于训练人工智能模型的人那里收集的数据。
生成高质量教学数据的高级方法
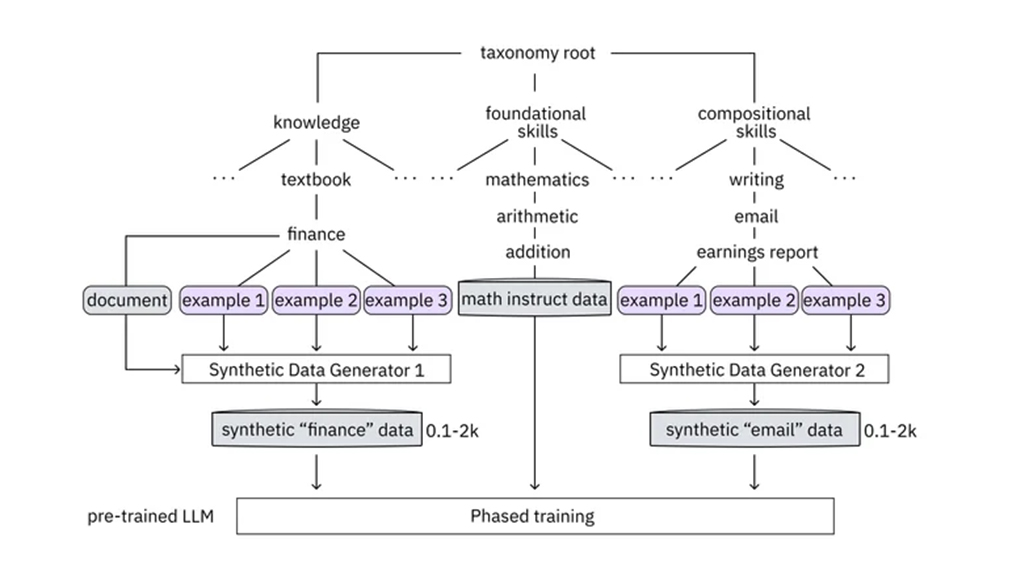
* IBM生成高质量指令数据的方法依赖于一种分类法,该分类法使LLM开发人员能够为他们的聊天机器人指定所需的知识和技能。
*分类逻辑组织LLM的现有知识和技能,帮助开发人员识别和填补新的信息和技能的差距。
*二级LLM,教师模式,制定一流的指导问答对量身定制的任务。
*例如,训练聊天机器人起草CEO总结第三季度收益的电子邮件,将需要理解财务报表、基本的数学能力,以及适当总结财务数据的能力。
* IBM的分类法将指令数据分为三大类:知识、基础技能和组合技能。
*教师模式为每个类别生成指令,同时保持质量控制。
*在实践中,LLM开发人员上传相关的财务文件和计算公司收益的方法,允许教师模型根据这些数据生成指令。
*此外,教师模型根据提供的收益报告电子邮件样本,提供计算收益和编写所需电子邮件的说明。
*教师模型严格检查生成数据的质量,丢弃不相关的问题和包含不准确的指令。
*经过审查的指令分为知识、基础技能和作曲技能,准备分阶段提供给LLM。
*这种毕业培训方法使LLM能够逐步建立在其现有的知识和技能,类似于人类学习的进展。
LAB方法的影响
IBM研究院利用LAB方法生成了一个包含120万条指令的合成数据集。两个开源LLM,Labradorite 13B(基于Meta的Llama-2-13B模型)和Merlinite 7B(基于Mistral 7B模型),在该数据集上进行了训练。对齐的模型在各种基准(包括连贯的对话和常识推理)上展示了与最先进的聊天机器人的竞争力。
LAB的两个关键特性促成了这些令人印象深刻的结果。
*首先,教师模型从分类学的每个叶节点生成合成样例,与随机抽样方法相比,目标任务的覆盖范围更广。
*其次,LAB可以在基础LLM中添加新的知识和技能,而无需将这些信息集成到教师模型中。IBM研究院人工智能模型副总裁大卫·考克斯(David Cox)表示,这消除了对全能教师模型的需求,将其功能提炼到基本模型中。
LAB允许LLM开发人员创建指令,而不必担心使用GPT-4等专有LLM生成合成数据的合法性。IBM的LAB方法源于团队的认识,即卓越的校准数据可以增强为企业需求量身定制的更小、更具成本效益的模型的功能。虽然预训练仍然至关重要,但为模型提供高度精心策划的特定任务指令也同样重要。
常见问题
1.什么是合成数据?
合成数据是指人工制造的信息,不同于来自真实世界的数据。它是通过算法生成的,可以替代从生产或操作数据中获得的测试数据集。合成数据用于验证数学模型和训练机器学习(ML)模型。
获取高质量的真实数据具有挑战性、昂贵且耗时。然而,合成数据技术允许用户快速、方便、数字化地生成任何所需数量的数据,以满足他们的特定要求。
2.为什么合成数据很重要?
由于合成数据比真实数据具有许多优点,因此越来越受到人们的欢迎。根据Gartner的预测,到2024年,用于开发人工智能和分析的数据中有60%将是人工产生的。
合成数据的主要应用是训练神经网络和机器学习模型。开发人员需要精心标记的数据集,从几千到数千万个项目不等。合成数据可以模拟真实数据集,使公司无需大量时间和财务投资即可生成多样化和广泛的培训数据。
3.生成高质量教学数据的方法是如何工作的?
该方法依赖于逻辑组织现有知识和技能的分类法。二级LLM,即教师模式,根据任务制定指导。这些指导分为知识、基础和组合技巧,在整个过程中保持质量控制。
4. LAB方法的主要特点是什么?
LAB方法支持从分类法的每个叶节点生成合成数据,从而提供更广泛的目标任务覆盖范围。此外,它允许在基础LLM中添加新的知识和技能,而无需将这些信息集成到教师模型中,从而提高灵活性和效率。
5. LAB方法如何影响聊天机器人的性能?
利用LAB方法,研究人员生成了一个合成数据集,并训练了开源LLM,从而在各种基准测试中获得了具有竞争力的表现。该方法显著增强了聊天机器人的能力,为训练和提高聊天机器人的性能提供了一种经济高效的解决方案。
6. LAB方法在聊天机器人开发中的优势是什么?
LAB方法提供了一种系统的方法来克服现代聊天机器人的挑战。它减少了与培训LLM相关的时间和成本,确保了更强大的性能,并允许在不受限制的情况下添加新的知识和技能,从而重塑了会话式人工智能的前景。
 Apple 苹果 MacBook Pro M3版 14英寸 轻薄本 深空黑色(M3 Pro 11+14
Apple 苹果 MacBook Pro M3版 14英寸 轻薄本 深空黑色(M3 Pro 11+14
 NORTH BAYOU H100 显示器支架 22-35英寸
NORTH BAYOU H100 显示器支架 22-35英寸
 紫枚 iPhone系列 透明磁吸手机壳
紫枚 iPhone系列 透明磁吸手机壳
 SanDisk 闪迪 至尊高速系列 升级款 SD存储卡 256GB(UHS-I、C10)
SanDisk 闪迪 至尊高速系列 升级款 SD存储卡 256GB(UHS-I、C10)
 SanDisk 闪迪 E61至尊极速卓越版 移动固态硬盘 1TB
SanDisk 闪迪 E61至尊极速卓越版 移动固态硬盘 1TB
 TOSHIBA 东芝 新小黑A5系列 2.5英寸 USB3.2移动硬盘 4TB
TOSHIBA 东芝 新小黑A5系列 2.5英寸 USB3.2移动硬盘 4TB
 SHOKZ 韶音 OpenRun Air S803 骨传导蓝牙无线耳机
SHOKZ 韶音 OpenRun Air S803 骨传导蓝牙无线耳机
 MI 小米 Redmi 红米 Redmi buds 5 入耳式真无线动圈主动降噪蓝牙耳机 晴雪白
MI 小米 Redmi 红米 Redmi buds 5 入耳式真无线动圈主动降噪蓝牙耳机 晴雪白
 ulanzi MT-20 全景云台短款三脚架
ulanzi MT-20 全景云台短款三脚架







网友评论